ABSTRACT
In this paper, we report an algorithm that is designed to leverage the cloud as infrastructure to support Internet of Things (IoT) by elastically scaling in/out so that IoT-based service users never stop receiving sensors data. This algorithm is able to provide an uninterrupted service to end users even during the scaling operation since its internal state repartitioning is transparent for publishers or subscribers; its scaling operation is time-bounded and depends only on the dimension of the state partitions to be transmitted to the different nodes. We describe its implementation in E-SilboPS, an elastic content-based publish/subscribe (CBPS) system specifically designed to support context-aware sensing and communication in IoT-based services.
E-SilboPS is a key internal asset of the FIWARE IoT services enablement platform, which offers an architecture of components specifically designed to capture data from, or act upon, IoT devices as easily as reading/changing the value of attributes linked to context entities. In addition, we discuss the quantitative measurements used to evaluate the scale-out process, as well as the results of this evaluation. This new feature rounds out the context-aware content-based features of E-SilboPS by providing, for example, the necessary middleware for constructing dashboards and monitoring panels that are capable of dynamically changing queries and continuously handling data in IoT-based services.
GENERAL ARCHITECTURE
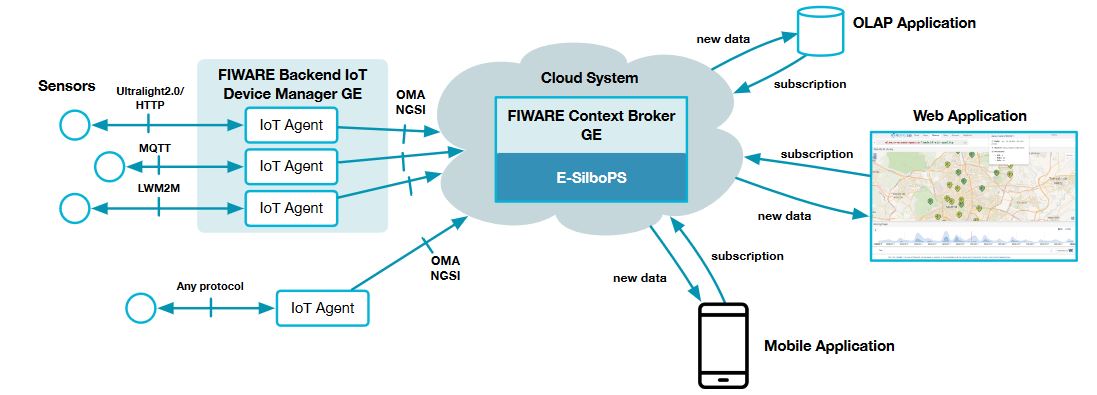
Figure 1. General architecture to support large scale IoT services
By using this architecture, as shown in Figure 1, IoT devices will be represented in a FIWARE platform as NGSI entities in the Context Broker. This means that you can query or subscribe to changes of device parameters status by querying or subscribing to the corresponding NGSI entity attributes at the Context Broker. E-SilboPS represents a key internal platform asset to achieve elasticity in the distribution of context information mediated by the Context Broker in a cloud-enabled environment.
RELATED WORK
In the context of WSN, the adoption of decentralized publish-subscribe services is already established. These approaches are complementary to our work and can use our system as a way to connect various IoT services. For example, the work in focuses on the internal WSN routing instead of the message distribution between IoT services, so it could benefit from using our solution to get connected to third party services.
CONCEPT
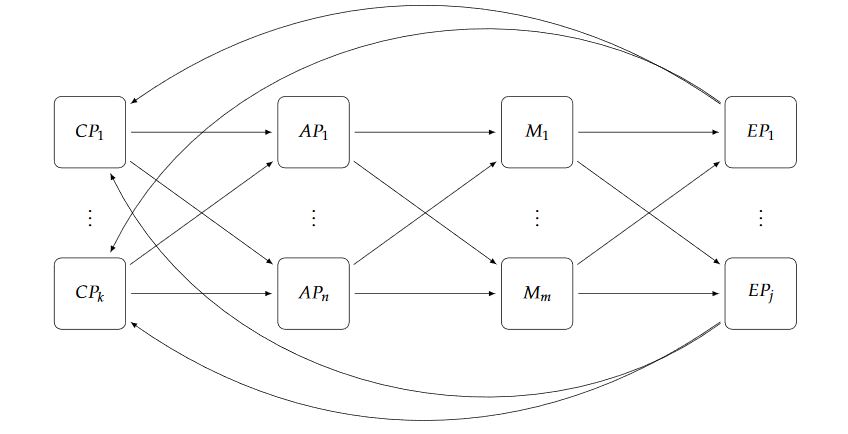
Figure 3. E-SilboPS architecture for the all layers: Connection Point, Access Point, Matcher and Exit Point
E-SilboPS is divided into four layers, as shown in Figure 3, similar to the engine described, and each operator layer can scale in and out independently of the others. Some orchestration between layers is needed, however, to maintain state consistency, and it is done by creating and removing nodes from the Distributed Coordinator (DC) in order to fire events to the interested layers; the DC is implemented using Zookeeper (We use ZooKeeper to ensure a reliable distributed coordination between operator slices.
THE ALGORITHM
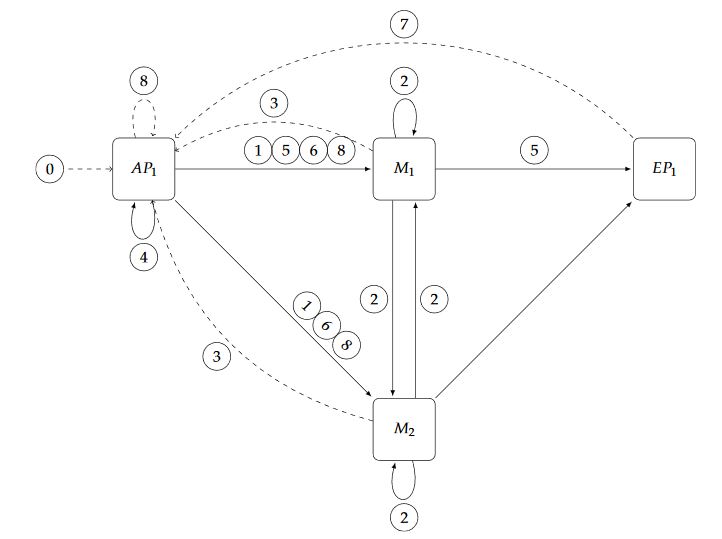
Figure 4. Messages exchanged during Matcher layer scale-out
As shown in Figure 4, the scaling of the Matcher layer requires coordination with the other two layers since Access Point will need to use a new selector and buffer subscriptions and notifications, whereas Exit Point will have to change their internal state to correctly collect notifications coming from the new Matcher configuration.
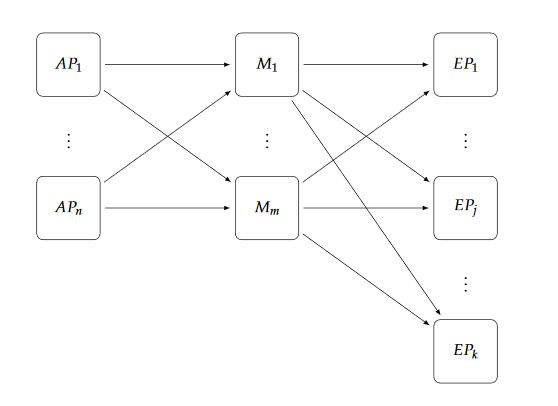
Figure 5. Exit Point layer scale-out: exit points from j + 1 to k are added to the current configuration
Exit Point layer scaling (see Figure 5) has to be coordinated with the Matcher layer because a consistent cut of notification must be done. Even though no direct mechanism of synchronization between matchers is required, each matcher has to perform a set of operations such that the added (or removed) exit point instances will be used only after a consistent change view.
EVALUATION
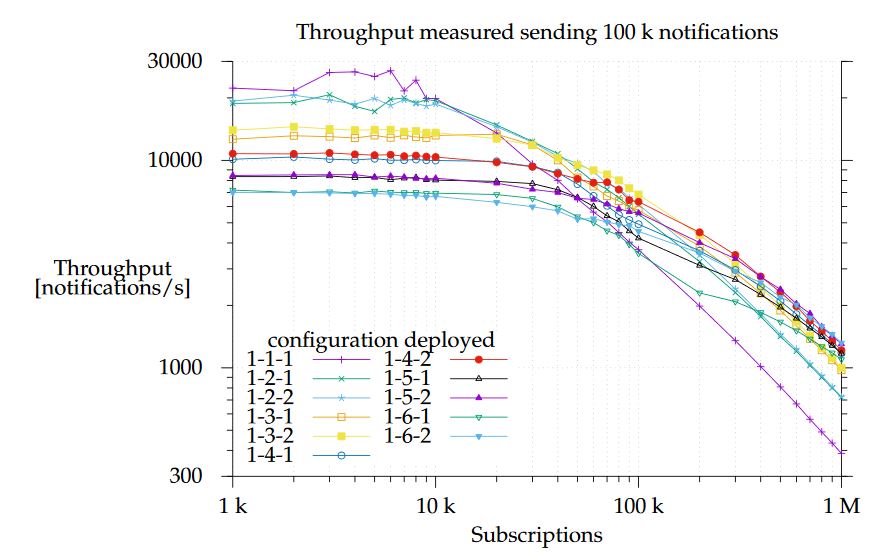
Figure 7. Notification throughput with different configurations
This is a worst-case scenario setup since the system has to deliver all the notifications, whereas, in a real environment, some notifications will not be delivered because no matching subscriptions will have been sent. As shown in Figure 7, when E-SilboPS was deployed with a 1-1-1 configuration, notification throughput started to slow down just after the system was loaded with 10 k subscriptions. It descended at a constant rate, and processing time started to be dominated by matching as of 20 k subscriptions. This means that the constant throughput on the left side of the graph is due to network saturation. This limits the amount of messages that an operator can process.
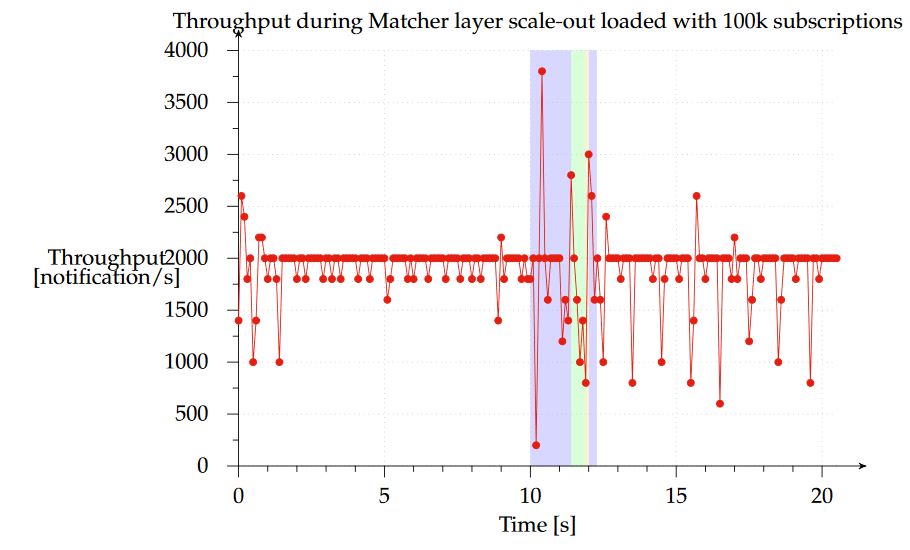
Figure 13. Notification throughput with subscriptions during scale-out of Matcher layer
Figure 13 shows the scale-out from the 1-1-1 to the 1-3-1 configuration. The red line represents notification throughput received from the subscriber and the highlighted blue region represents the time during which the system was scaling out. Clearly, the system continues to process notifications while the subscriptions are buffered in the access points and matchers are switching to their new state, after which the access point starts buffering notifications and flushes all its buffered subscriptions (green region). This phase is illustrated in the graph from seconds 11.4 to 11.9 (490 ms).
FUTURE WORK
E-SilboPS currently depends on an external system to decide when it has to scale in or out. This system has to make this decision based on current resource usage, as well as delivered performance. The use of metrics that measure only CPU or memory usage is not very suitable for a cloud system because they are only helpful for the technicians that manage the cloud. Users neither know nor care about how much CPU or how many machines are used, they are concerned about service quality such as Service Level Agreement (SLA), their user experience and billing cost. This means that the software that decides when to scale E-SilboPS in or out should have access to the above metrics and should possibly predict peaks of usage with respect to the SLA. At the same time, it should have knowledge of the performance efficiency and monetary cost of the current configuration, which should be optimum.
CONCLUSIONS
In this article, we have presented a proper elastic content-based publish/subscribe system that supports transparent, publisher-wise dynamic state repartitioning without client disconnection and with minimal notification delivery interruption for subscribers. As shown in the evaluation section, E-SilboPS can be successfully used as communication mechanism between IoT devices and any kind of application interested in the data generated by them that implements the proposed general architecture. Moreover, thanks to its elastically-scalable nature, it can sustain the large amount of data that today’s IoT services can generate.
Unlike other proposals such as, which focuses on fault tolerance and thus requires more space to store the redundant state and also a more complex algorithm for execution by the Access Point layer, which is really a re-implementation of an application-specific version of the VM migration capability offered by today’s hypervisors, we described the full algorithm that we validated with qualitative and quantitative measurements. This demonstrated that dynamic state re-partitioning is not only possible but also achievable even from the performance point of view. Finally, note that the reported research is being developed and applied as part of the 4CaaSt, FIWARE and FICORE EU FP7 projects, where Publish/Subscribe is offered as both a value-added service to hosted applications and a key internal platform asset.
Source: Cambridge University
Authors: Sergio Vavassori | Javier Soriano | Rafael Fernandez
>> 200+ IoT Led Engineering Projects for Students
>> IoT Software Projects for Engineering Students